NLP experiment
![]() Этот текущий проект представляет собой попытку построить NLP-классификатор для продуктов из супермаркетов, используя их название. Используются следующие технологии:
Этот текущий проект представляет собой попытку построить NLP-классификатор для продуктов из супермаркетов, используя их название. Используются следующие технологии:
- Backend - Django, Django REST framework
- Fronend - React, HTML, CSS (Bulma)
- Machine learning: Pytorch, transformers, scikit-learn
- Data handling - pandas, matplotlib
Главной сложностью этого проекта является то, что данные представлены более чем на 20 языках, в связи с чем была использована известная модель, натренированная на более чем 100 языках - XLMRoberta. Я провел тонкую настройку (fine-tuned) эту модель для поставленной задачи. В дальнейшем я планирую добавить к входным данным информацию о бренде, изображение, вес/объем товара к существующей модели с использованием ансамблевых методов для достижения лучших результатов.
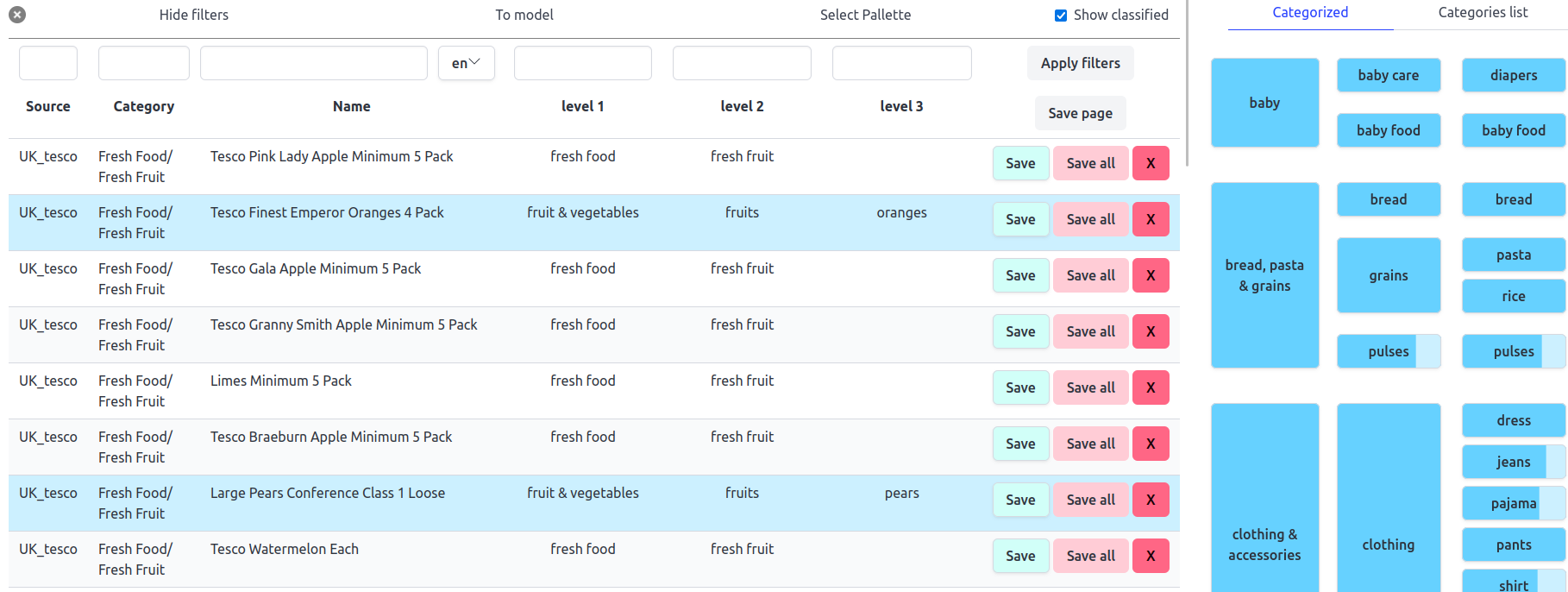
Важной частью этого проекта является инструмент для очистки данных, который используется для фильтрации, очистски и обозначения данных. Этот web-инструмент создан с использованием Django, ео интерфейс представлен на изображении ниже: